Hướng dẫn tạo file robots.txt chuẩn dành cho WordPress

Th8
Tiếp tục các bài viết về chủ đề thủ thuật SEO thì mình sẽ giới thiệu Robots.txt là gì? và Cách tạo file robots.txt cho mã nguồn WordPress, các bạn chú ý theo dõi để có thể hoàn tất các bước tối ưu hóa SEO cho website của mình nhé.

Robots.txt là gì?
Robots.txt là một tập tin đặc biệt chứa văn bản (không phải HTML) được đặt trong thư mục root của website (ngang hàng với index.php).
Robots.txt có tác dụng cho phép hay không cho phép các công cụ tìm kiếm truy cập đến những trang mà bạn quy định trong trong nó, giúp cho những trang này nhanh chóng được index hoặc không được index trên các kết quả tìm kiếm. Đây chính là một công cụ cực kì hữu ích giúp tăng tốc độ index trong quá trình Làm SEO.
Đặt một file robots.txt trong thư mục gốc của tên miền cho phép bạn ngăn chặn công cụ tìm kiếm lập chỉ mục các tập tin và thư mục nhạy cảm. Ví dụ, bạn có thể ngăn chặn một công cụ tìm kiếm thu thập dữ liệu từ thư mục hình ảnh của bạn hoặc lập chỉ mục một tập tin PDF nằm trong một thư mục bí mật.
Các công cụ tìm kiếm “lớn” sẽ thực hiện theo các quy tắc mà bạn thiết lập. Tuy nhiên, không phải lúc nào các quy tắc mà bạn xác định trong tập tin robots.txt cũng được thi hành. Trình thu thập dữ liệu của các phần mềm độc hại và các công cụ tìm kiếm “nhỏ” có thể không tuân thủ các quy tắc và index bất cứ điều gì họ muốn. Rất may, các công cụ tìm kiếm “lớn” hoạt động theo các tiêu chuẩn này, bao gồm cả Google, Bing, Yandex, Ask và Baidu.
Một tập tin robots.txt có thể được tạo ra trong vài giây. Tất cả những gì bạn phải làm là mở một trình soạn thảo văn bản (NotePad hoặc NotePad++) và lưu một tập tin trống với tên robots.txt. Sau khi thêm một số “quy tắc” vào tập tin, lưu nó lại và upload lên thư mục gốc của tên miền, tức là tại địa chỉ http://yourwebsite.com/robots.txt. Hãy đảm bảo bạn đã upload tập tin robots.txt vào thư mục gốc của tên miền, ngay cả khi WordPress được cài đặt trong một thư mục con.
Công cụ tìm kiếm sẽ kiểm tra tập tin robots.txt ở thư mục gốc của tên miền mỗi khi chúng bắt đầu tiến hành thu thập thông tin từ blog/ website của bạn. Lưu ý, bạn cần phải tạo các file robots.txt riêng biệt cho mỗi tên miền phụ và các giao thức khác nhau.
Không mất quá nhiều thời gian để có được một sự hiểu biết đầy đủ về Robots.txt. Chỉ có một vài quy tắc để bạn tìm hiểu. Những quy tắc này thường được gọi là “chỉ thị”.
Cấu trúc cơ bản của file Robots.txt
- User-agent: xác định các công cụ tìm kiếm mà quy tắc được áp dụng.
- Disallow: ngăn cản các công cụ tìm kiếm không thu thập thông tin và lập chỉ mục.
- Allow: cho phép các công cụ tìm kiếm không thu thập thông tin và lập chỉ mục.
Dấu hoa thị (*) có thể được sử dụng như một ký tự đại diện cho tất cả các công cụ tìm kiếm. Ví dụ, bạn có thể thêm dòng sau vào file robots.txt để ngăn chặn các công cụ tìm kiếm thu thập thông tin trên toàn bộ blog/ website của bạn.
User-agent: * Disallow: /
Các chỉ thị trên là hữu ích nếu bạn đang phát triển một blog/ website mới và không muốn các công cụ tìm kiếm lập chỉ mục khi nó chưa được hoàn thiện.
Một số blog/ website sử dụng chỉ thị Disallow mà không có dấu gạch chéo (/) để biểu thị một trang web có thể được thu thập dữ liệu. Điều này cho phép các công cụ tìm kiếm có đầy đủ quyền truy cập vào toàn bộ blog/ website của bạn.
User-agent: * Disallow:
Để ngăn chặn việc thu thập dữ liệu với các thư mục hoặc đường dẫn cụ thể, bạn chỉ cần thêm đường dẫn hoặc tên thư mục vào sau chữ Disallow . Trong ví dụ dưới đây, tôi đã quy định các công cụ tìm kiếm không được phép thu thập thông tin của thư mục /images/ và toàn bộ các tập tin cũng như thư mục con chứa trong nó:
User-agent: * Disallow: /images/
Điều này có được là do robots.txt sử dụng đường dẫn tương đối, không sử dụng đường dẫn tuyệt đối. Các dấu gạch chéo (/) thay thế cho thư mục gốc của tên miền và do đó áp dụng quy tắc cho toàn bộ blog/ website của bạn. Đường dẫn là trường hợp nhạy cảm, vì vậy hãy chắc chắn sử dụng đúng trường hợp khi xác định các tập tin, các trang và thư mục.
Các User Agent của Google
Google có vài User Agent chính với những nhiệm vụ khác nhau. Bạn có thể ngăn chặn chúng không cho truy cập vào website với dòng lệnh User-agent tương ứng trong file robots.txt. Tuy nhiên chúng ta không nên làm việc này, chỉ hiểu để biết thôi nhé, nếu có chặn thì hãy chặn những Spam Bot thôi.
- Googlebot: Đánh chỉ số từ các chỉ mục mới và cũ.
- Googlebot-Mobile: Đánh chỉ số cho thiết bị di động.
- Googlebot-Image: Đánh chỉ số cho các file ảnh.
- Mediapartners-Google: Xuất hiện trong các trang dăng quảng cáo của Google Adsense.
- Adsbot-Google: Đánh chỉ số các trang được nhà quảng cáo sử dụng giới thiệu sản phẩm hay dịch vụ thông qua Google Adwords. Nó cho phép đánh giá chất lượng của trang dùng dịch vụ Adwords.
Mẫu file robots.txt chuẩn dành cho WordPress
Đây là một trong những mẫu file robots.txt chuẩn nhất, tối ưu nhất, được nhiều blogger WordPress nổi tiếng tin dùng. Bạn cũng có thể sử dụng nó cho blog/ website WordPress của mình. Tuy nhiên, hãy nhớ tùy biến nó cho phù hợp với từng hoàn cảnh cụ thể.
User-agent: * Disallow: /wp-admin/ Disallow: /readme.html Disallow: /license.txt Allow: /wp-admin/admin-ajax.php Allow: /wp-admin/images/* Sitemap: https://muatheme.com/sitemap_index.xml
Lưu ý:
- Thay https://muatheme.com/sitemap_index.xml bằng đường link đến XML sitemap của bạn.
- Không nên chặn Google và các công cụ tìm kiếm khác thu thập dữ liệu trong các thư mục /wp-content/themes/ và /wp-content/plugins/. Điều đó sẽ cản trở việc Google có một cái nhìn chính xác nhất về giao diện blog/ website của bạn.
Kết luận
Như vậy là chúng ta đã tìm hiểu về cấu trúc của robots.txt và cách tạo file robots.txt rồi. Tuy đây là một tập tin đơn giản những có chức năng rất quan trọng giúp những công cụ tìm kiếm dễ dàng index những thông tin nóng hổi trên trang web của bạn thường xuyên nhất.
Bài viết cùng chủ đề:
-

Thêm nút Mua Ngay vào Woocommerce một cách đơn giản
-

Chuyển 0đ thành chữ “Liên hệ” trong woocommerce
-

Chia sẻ cách làm menu đa cấp cho Flatsome
-
Cách thêm mục lục (table of content) cho mô tả danh mục sản phẩm
-

Xoá bỏ thẻ p và br trong CF7
-

Sửa lỗi icon loading không tự mất đi của Contact Form 7 khi sử dụng theme Flatsome
-

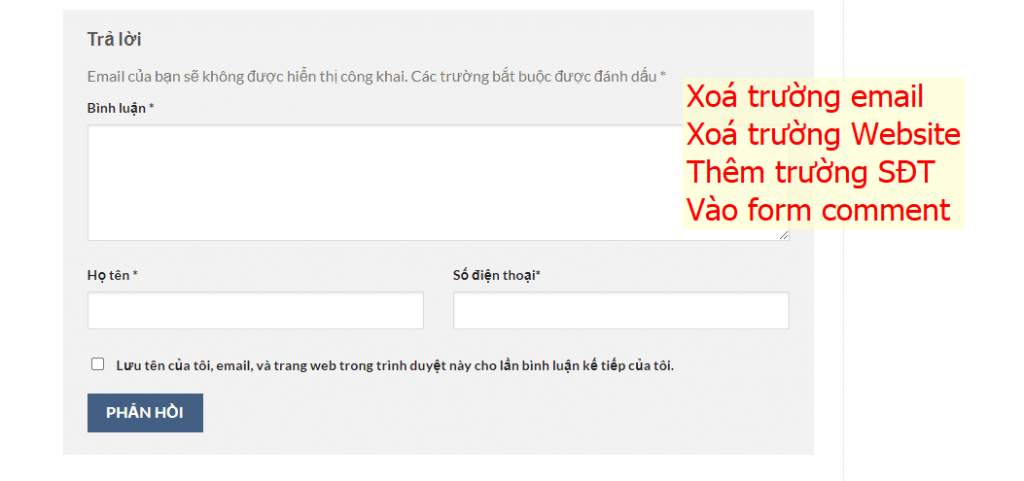
Thêm trường số điện thoại, xoá trường email, website trong comment form
-

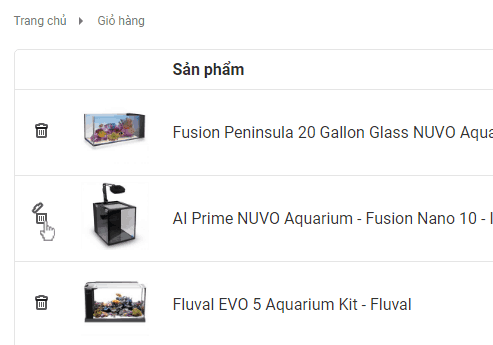
Làm đẹp cho nút xóa sản phẩm trong woocommerce
-
Chia sẻ cách chống SPAM cho Contact Form 7 hiệu quả nhất
-

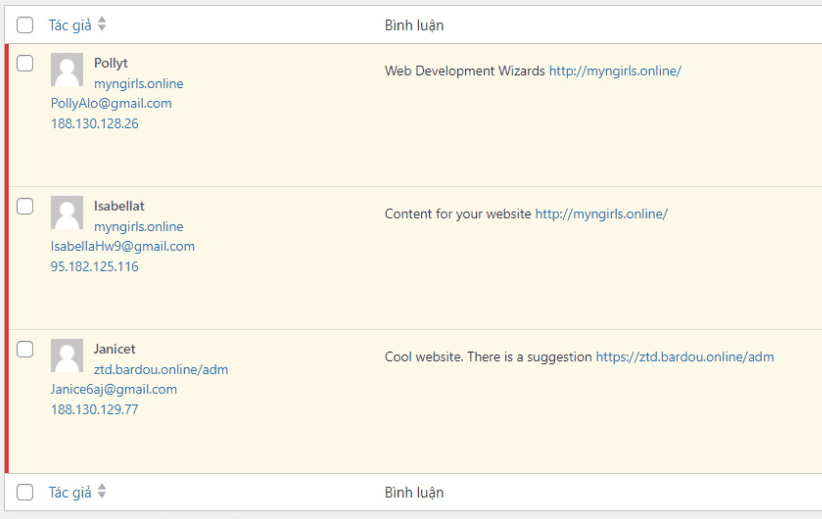
Chia sẻ mẹo nhỏ để chặn comment spam trong WordPress
-
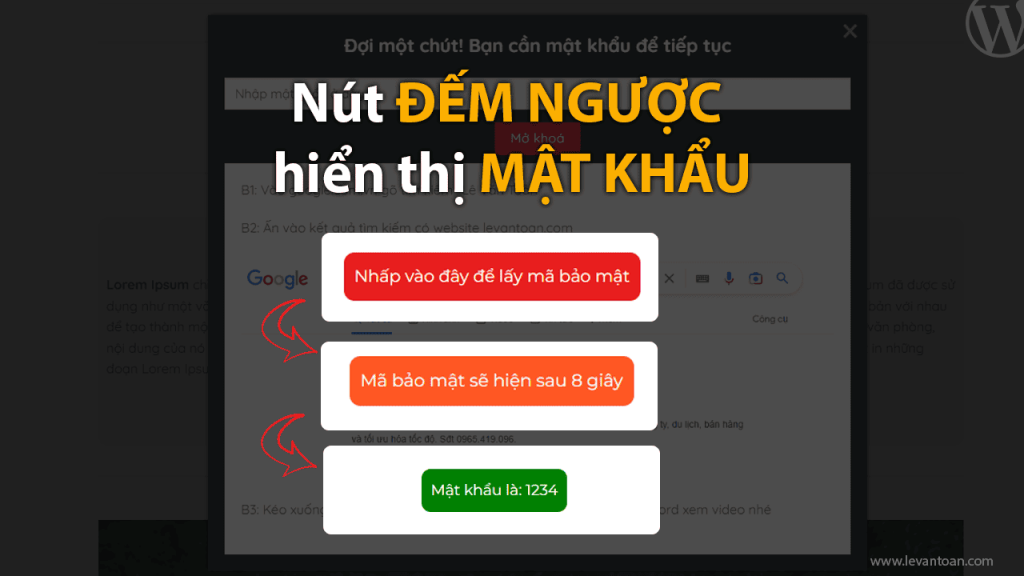
Chia sẻ nút đếm ngược để hiển thị mật khẩu trong WordPress
-

Hướng dẫn thay đổi cách hiển thị giá và mô tả ngắn của biến thể trong Woo
-

Thêm nút Mua Ngay vào sản phẩm woocommerce wordpress
-

Thêm bài viết liên quan theme flatsome wordpress
-

Thêm chat fanpage facebook vào website wordpress
-

Hướng dẫn chèn comment facebook vào website wordpress